The most expensive part of your AI product isn't the model - it's the architecture you built to keep it alive
Scenario:
Last Black Friday, a client’s AI powered pricing engine triggered $20,000 in cloud overage in just 48 hours. The culprit? A recursive retry loop in their realtime inference pipeline. The model itself worked exactly as designed. The problem was the architecture surrounding it.
Architects know this story too well: AI does not fail gracefully. It magnifies every latent design flaw data bottlenecks, latency spikes, and runaway costs. This article cuts past the hype to focus on the decisions that actually determine if an AI product survives production, backed by hard-earned post-mortem lessons.
Quick summary (for busy readers)
- Execution is Economics: Real-time AI is a financial risk. If you don't have economic circuit breakers at the API Gateway level, a bug can bankrupt a project in a weekend.
-
Avoid the VDB Trap: Don't buy a specialized Vector Database until you've proven that
pgvector(Postgres) or your existing search engine can't handle the OpEx and latency requirements. - Models are Code: If your model isn't versioned, tested via CI/CD, and capable of an automated rollback, it isn't a production artifact - it's an experiment.
- Design for Drift: AI is probabilistic. If you aren't monitoring for silent output degradation (drift), your system will eventually lie to your users without triggering a single "Error 500."
1. Deployment Pattern: Real-Time, Batch, or Streaming
The Architect’s Dilemma: Sub-second inference is rarely free. Serverless GPU functions look attractive, but cold-start latency and provisioning delays often blow SLAs when traffic spikes.
- Hidden trap: Treating serverless AI functions as “always available.” This leads to request queuing, which triggers client retries, leading to a death spiral of cost and latency.
- Trade-off: Batch inference is cheap and stable but useless for interactive UX. Streaming pipelines are resilient but introduce significant orchestration overhead.
Post-mortem — “The $20,000 Weekend”:
A fraud detection model was deployed on ephemeral GPU instances. During a traffic spike, cold starts triggered a 5-second delay. The calling service retried every 1 second. The cloud bill doubled before the on-call engineer even logged in. The fix wasn’t a better model; it was implementing pre-warmed instances and aggressive request throttling.
2. Data Architecture and the Vector DB Trap
AI systems are essentially data pipelines with an expensive, probabilistic function in the middle. If your plumbing leaks, your model is irrelevant.

The Vector DB trap: Specialized vector databases are the “shiny toy” of the year. However, their OpEx is high. In 90% of use cases, an extension like PGVector on your existing Postgres instance provides 100% of the required functionality at a fraction of the cost.
Feature consistency: Without a proper feature store, the data used for training will differ from the data seen at inference time (training-serving skew), causing models to fail in ways that are nearly impossible to debug.
Post-mortem — “The RAG Bottleneck":
A knowledge retrieval system used a fully managed vector DB. Query latency hit 3 seconds at peak. By migrating to Postgres + PGVector, the team halved latency and reduced infrastructure costs by 75%, simply by keeping the embeddings closer to the primary application data.
3. Model Management and Lifecycle Complexity
Models are production artifacts, not static scripts. Treating them as “special” usually means they bypass the rigor of standard software engineering.
- Versioning pitfalls: Deploying a “better” model version without a side-by-side (A/B) test or a clear rollback path is a recipe for silent failure.
- CI/CD for ML: Automated testing must include “model evaluation” steps. Does the new version still pass the gold-standard test set, or did it trade general accuracy for a specific performance gain?
Post-mortem — “The Hallucinating Support Bot”:
A fraud detection model was deployed on ephemeral GPU instances. During a traffic spike, cold starts triggered a 5-second delay. The calling service retried every 1 second. The cloud bill doubled before the on-call engineer even logged in. The fix wasn’t a better model; it was implementing pre-warmed instances and aggressive request throttling.
4. Scalability, Latency, and Economic Circuit Breakers
AI architecture is unique because a logic bug can have immediate, five-figure financial consequences. Traditional auto-scaling focuses on availability; AI scaling must focus on economic survival.
Token Budgets: Implement hard limits on the number of tokens a specific user, session, or tenant can consume. This prevents “prompt injection” or recursive loops from draining your budget.
Tiered Fallbacks: When latency spikes or primary GPU clusters are full, the architecture should automatically fall back to a “smaller” model (e.g., falling back from a 70B parameter model to an 8B model). This preserves UX at the cost of a temporary dip in intelligence.
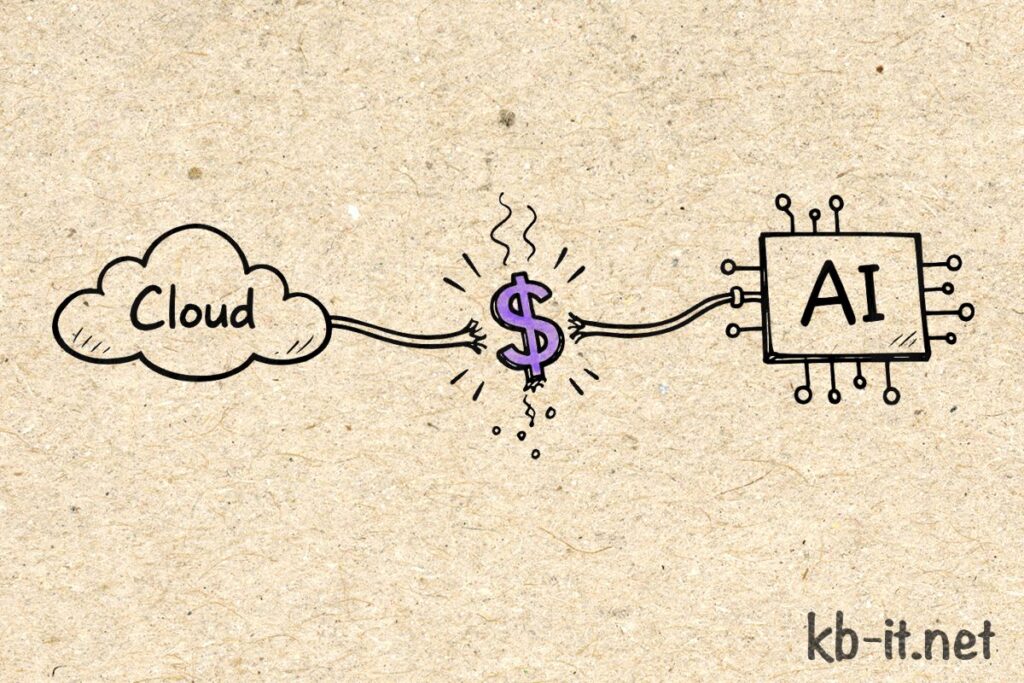
The API Gateway Guard: Economic circuit breakers should live at the Gateway level. If the cost-per-minute exceeds a threshold, the system should kill the connection before the cloud provider’s billing department does.
Feature consistency: Without a proper feature store, the data used for training will differ from the data seen at inference time (training-serving skew), causing models to fail in ways that are nearly impossible to debug.
Takeaway:
Scalability in AI isn’t just about handling load; it’s about Financial Engineering. You need the ability to “degrade gracefully” rather than “spend infinitely.“
5. Observability, Guardrails, and Drift
Because AI is probabilistic, it will eventually produce an answer that is technically “valid” but practically wrong or dangerous.
- Silent Drift: A model that worked in January might be useless in June because the underlying user behavior has changed. You need automated alerts that flag when the distribution of model outputs shifts significantly.
- Input/Output Guardrails: These are deterministic “wrappers” around the AI. If the model generates a response containing restricted words or PII, the guardrail blocks the output regardless of what the model intended.
Analogy:
Observability is your system’s shock absorber. Without it, every “probabilistic surprise” becomes a catastrophic jolt to the business.
Conclusion:
The Architect as Risk Manager
Success in AI isn’t about choosing the most sophisticated model; it’s about building a ship that stays afloat even when the engine (the model) behaves unpredictably. The most successful AI products aren’t those with the highest accuracy, they are the ones with the lowest Mean Time to Contain (MTTC) when things go wrong.
Actionable next step:
This Friday, run a “Pre-Mortem” with your team. Ask: “If we woke up to a $50,000 cloud bill tomorrow morning, which specific architectural loop allowed it to happen?” Then, go build the circuit breaker that prevents it.